Übungen zur medizinischen
Biometrie
2 Deskriptive Statistik I
Aufgabe der deskriptiven Statistik ist
es, die in den Daten der Stichprobe enthaltene
Information übersichtlich und unverfälscht in Tabellen,
Grafiken und statistischen Maßzahlen zusammenzufassen.
Wie das zu geschehen hat, hängt entscheidend vom Typ des
betrachteten Merkmals ab.
2.1
Lernziele zu
Kapitel 2
- tabellarische und graphische
Darstellung der Daten eines qualitativen
Merkmals
- tabellarische und graphische Darstellung der Daten
eines quantitativen Merkmals
- statistische Maßzahlen
- Lagemaße
- Streuungsmaße
- empirische Verteilungsfunktion
- Häufigkeitsmaße in der Epidemiologie
2.2 Tabellarische
und graphische Darstellung bei qualitativen Merkmalen
Im wesentlichen wird die Auswertung
qualitativer Merkmale hier auf die Darstellung der
absoluten bzw. der relativen Häufigkeiten beschränkt.
Sei A ein qualitatives Merkmal
mit den Ausprägungen A1,...,Ak.
In einer Stichprobe vom Umfang n habe man die
Ausprägung Ai mit der
absoluten Häufigkeit ni
beobachtet (i=1,2,.....,k).
Bei n0 Beobachtungseinheiten
aus der Stichprobe fehle die Angabe zum Merkmal A.
Dann ist offenbar
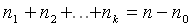 .
.
Unter den relativen Häufigkeiten,
genauer den adjustierten relativen Häufigkeiten,
versteht man
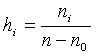 (i = 1,2,...,k).
(i = 1,2,...,k).
Der Zusatz "adjustiert" soll
betonen, dass man bei der Berechnung nur diejenigen
Beobachtungseinheiten berücksichtigt, bei denen die
Angaben zum Merkmal A tatsächlich vorliegen.
Meist werden die relativen Häufigkeiten in Prozent
angegeben:
hi
= hix100%,
also z. B. 30 % statt 0.3.
Eine Tabelle der adjustierten relativen
Häufigkeiten sollte stets auch den Stichprobenumfang und
die Anzahl bzw. den Anteil fehlender Werte enthalten.
Beispiel 2.1
Bei einer Stichprobe von Patienten, die
unter Krampfadern im Unterschenkelbereich litten, wurde
eine Salbe zur Linderung der Beschwerden angewandt. Eine
halbe Stunde nach Auftragen der Salbe wurden die
Patienten befragt, ob eine Besserung eingetreten sei. Es
ergab sich folgende Urliste:
Tabelle
2.1: Urliste für das Merkmal Besserung nach Salbenbehandlung
| Patient |
Besserung | Patient |
Besserung |
| 1 |
gering | 13 |
gering |
| 2 |
deutlich | 14 |
gering |
| 3 |
gering | 15 |
keine |
| 4 |
deutlich | 16 |
keine Angabe |
| 5 |
gering | 17 |
gering |
| 6 |
keine | 18 |
deutlich |
| 7 |
deutlich | 19 |
deutlich |
| 8 |
deutlich | 20 |
gering |
| 9 |
keine Angabe | 21 |
keine Angabe |
| 10 |
gering | 22 |
gering |
| 11 |
keine | 23 |
gering |
| 12 |
keine Angabe | 24 |
deutlich |
Aus dieser Urliste ergibt sich die folgende Tabelle der
absoluten und der relativen Häufigkeiten.
Tabelle
2.2: Häufigkeiten für das Merkmal Besserung nach Salbenbehandlung
| Besserung |
absolute Häufigkeit
|
relative Häufigkeit
|
adjustierte
relative Häufigkeit |
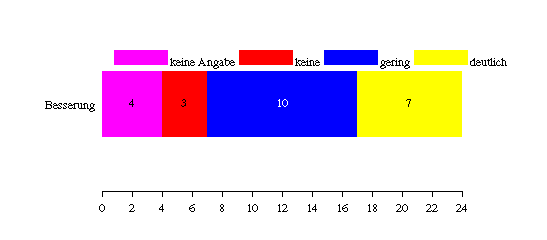
| keine |
3 |
12.5% |
15% |
| gering |
10 |
41.7% |
50% |
| deutlich |
7 |
29.2% |
35% |
| keine Angabe |
4 |
16.6% |
|
| Gesamt:
|
24 |
100% |
100% |
Für die graphische Darstellung gibt es viele Varianten.
Am einfachsten ist das Blockdiagramm. Die
Merkmalsausprägungen werden an einer Achse in beliebiger
(nominales Merkmal) bzw. in der natürlichen Reihenfolge
(ordinales Merkmal) angetragen. Darüber wird ein Block
gezeichnet, dessen Höhe der absoluten bzw. der relativen
Häufigkeit der Ausprägung entspricht. Die Breite der
Blöcke ist beliebig, sie soll aber für alle Blöcke
gleich sein.
Abbildung2.1: Blockdiagramm für das Merkmal Besserung nach Salbenbehandlung
 Bei einem Kreisdiagramm entspricht der absoluten bzw. der relativen
Häufigkeit der Ausprägung der zentrale Winkel des zugeordneten Kreissegments.
Bei einem Kreisdiagramm entspricht der absoluten bzw. der relativen
Häufigkeit der Ausprägung der zentrale Winkel des zugeordneten Kreissegments.
Abbildung 2.2: Kreisdiagramm für das Merkmal Besserung nach Salbenbehandlung
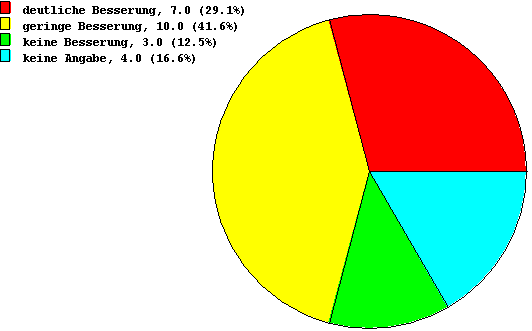
Bei einem Flächendiagramm entspricht der absoluten bzw. der relativen
Häufigkeit der Ausprägung der Flächeninhalt des zugeordneten Segments.
Abbildung 2.3: Flächendiagramm für das Merkmal Besserung nach Salbenbehandlung
 Applet - Graphische Darstellung von qualitativen Merkmalen
Applet - Graphische Darstellung von qualitativen Merkmalen
2.3
Tabellarische
und graphische Darstellung bei quantitativen Merkmalen
Die Darstellung für ein quantitativ diskretes Merkmal folgt im wesentlichen
der bei den qualitativen Merkmalen. Zusätzlich werden
die absoluten und die relativen Häufigkeitssummen
betrachtet, die definiert sind als
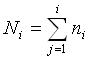 (i
= 1,2,...,k) absolute
Häufigkeitssumme,
(i
= 1,2,...,k) absolute
Häufigkeitssumme,
 (i
= 1,2,...,k) relative
Häufigkeitssumme.
(i
= 1,2,...,k) relative
Häufigkeitssumme.
Diese Definition benutzt die Tatsache, dass die
Ausprägungen eines quantitativ diskreten Merkmals stets in
natürlicher Weise von den kleinen zu den großen Werten
geordnet sind. Ni bzw. Hi
geben dann Antwort auf die Frage, wie groß die Anzahl
bzw. der Anteil der Beobachtungseinheiten mit
Ausprägungen kleiner oder gleich der i-ten Ausprägung ist (i = 1,2,...k). Die geeignete graphische Darstellung für die Häufigkeiten bei einem diskreten Merkmal ist das im wesentlichen dem Blockdiagramm entsprechende Stabdiagramm
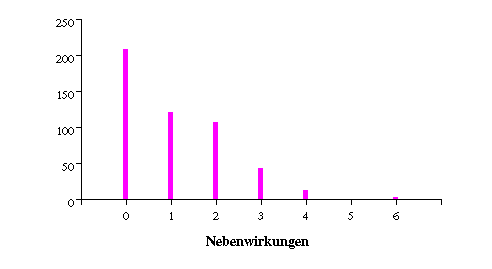
Beispiel 2.2
In einer Therapiestudie wurden die Häufigkeiten für das diskrete Merkmal Anzahl der gemeldeten Nebenwirkungen ermittelt. Tabelle 2.3 enthält das Ergebnis. In Abbildung 2.4 sind die Häufigkeiten als Stabdiagramm dargestellt.
Tabelle
2.3: Häufigkeiten für das quantitativ diskrete Merkmal Anzahl der Nebenwirkungen
Anzahl
der Nebenwirkungen |
absolute
Häufigkeit |
relative
Häufigkeit (%) |
absolute
Häufigkeitssumme |
relative
Häufigkeitssumme |
0 |
209
|
41.8%
|
209 |
41.8% |
1 |
122
|
24.4%
|
331 |
66.2% |
2 |
108
|
21.6%
|
439 |
87.8% |
3 |
44
|
8.8%
|
483 |
96.6% |
4 |
13
|
2.6%
|
496 |
99.2% |
5 |
0
|
0.0%
|
496 |
99.2% |
6 |
4
|
0.8%
|
500 |
100.0% |
Abbildung 2.4: Stabdiagramm für das Merkmal Anzahl gemeldeter Nebenwirkungen
Applet - Explorative Datenanalyse -- Datensatz "AML" - Stabdiagramm "Anzahl der Geschwister"
Wenn man die Häufigkeitsverteilung
eines quantitativ stetigen Merkmals tabellarisch oder graphisch
darstellen will, muss man das Merkmal klassieren. Das
bedeutet, man zerlegt den gesamten Wertebereich des
Merkmals in k Klassen. Die Klassengrenzen
bezeichnet man mit a0<a1<...<ak.
ai-ai-1
(i = 1,2,...k) ist die Breite der i-ten
Klasse, die man normalerweise für alle Klassen gleich
groß wählt. Wenn der Wertebereich des Merkmals
allerdings nach links bzw. rechts unbegrenzt ist, führt
man eine linke bzw. eine rechte Restklasse ein, die nach
links bzw. rechts unbegrenzt ist. Die Anzahl k der
Klassen sollte nicht zu groß und nicht zu klein sein.
Als Faustregel für die Wahl von k gilt
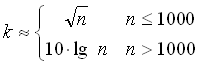 .
.
Die zugehörige graphische Darstellung
ist das Histogramm. Hier werden die absoluten oder die relativen
Häufigkeiten als Höhe eines Rechtecks über der gesamten
Klasse dargestellt.
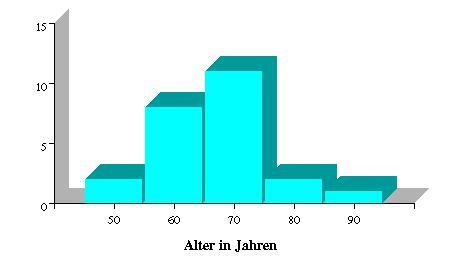
Beispiel 2.3
In Tabelle 2.4 liegen die bereits
klassierten Altersangaben von 25 Patienten einer
Klinischen Studie vor.
Tabelle
2.4: Häufigkeitsverteilung des
klassierten stetigen Merkmals
Alter in Jahren
| Klasse |
Alter in Jahren |
Klassenmitte |
Häufigkeiten
absolut /
relativ |
| 1 |
(45,55] |
50 |
2 |
2/24=.08 |
| 2 |
(55,65] |
60 |
8 |
8/24=0.33 |
| 3 |
(65,75] |
70 |
11 |
11/24=0.46 |
| 4 |
(75,85] |
80 |
2 |
2/24=0.08 |
| 5 |
(85,95] |
90 |
1 |
1/24=0.04 |
| Summe |
----- |
------ |
24 |
1 |
Die runde Klammer
besagt, dass die entsprechende Klassengrenze selbst nicht
zur Klasse gehört, die eckige Klammer zeigt an, dass die
entsprechende Klassengrenze dazugehört.
Das zugehörige Histogramm ist in Abbildung 2.5 zu sehen
Abbildung 2.5: Histogramm für das Merkmal Alter in Jahren
Applet - Histogramm mit veränderbarer Klassenbreite
Applet - Histogramm
und Normalverteilungsplot
Applet - Explorative Datenanalyse -- Datensatz "AML" - Histogramm "Größe"
2.4 Statistische Maßzahlen
Liegen Daten xi
zu einem quantitativen Merkmal vor, läßt sich die darin
enthaltene Information, übersichtlich in sogenannten
statistischen Maßzahlen zusammenfassen. Man unterscheidet Lagemaße und Streuungsmaße.
Lagemaße charakterisieren den Durchschnitt von Daten. Die bekanntesten Lagemaße sind der
arithmetische Mittelwert 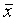 :
:
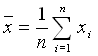
und der empirische Median 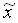 .
.
Zur Berechnung
des empirischen Medians müssen die Daten der Größe
nach geordnet werden, d. h. man geht von der Urliste der
Daten x1, x2,
..., xn zur Rangliste x(1)  x(2)
...
x(n)
über, indem man die Daten der Größe nach ordnet, (i)
heißt Rangzahl. Die Rangzahl gibt den Platz auf der Rangliste
an. (1) ist die Rangzahl des kleinsten Wertes, (n) ist
die Rangzahl des größten Wertes. Der empirische Median
ist der Wert "in der Mitte" der Rangliste, d.
h. die Hälfte der Meßwerte sind kleiner bzw. größer als der Median.
x(2)
...
x(n)
über, indem man die Daten der Größe nach ordnet, (i)
heißt Rangzahl. Die Rangzahl gibt den Platz auf der Rangliste
an. (1) ist die Rangzahl des kleinsten Wertes, (n) ist
die Rangzahl des größten Wertes. Der empirische Median
ist der Wert "in der Mitte" der Rangliste, d.
h. die Hälfte der Meßwerte sind kleiner bzw. größer als der Median.
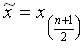 falls
n ungerade,
falls
n ungerade,
und
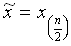 falls
n gerade.
falls
n gerade.
Oft verwendet man für ein gerades
n auch die Formel
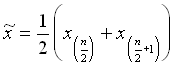 .
.
Beim Vergleich von Mittelwert und
empirischem Median stellt man fest, dass man zur
Berechnung des Mittelwertes alle Daten x1,
x2, ..., xn
vollständig kennen muss, während zur Berechnung des
empirischen Medians grob gesprochen die erste Hälfte der
Daten ausreicht.
Hat man z. B. eine Stichprobe vom
Umfang n=3 und kennt x1 = 2, x2
= 4, und von x3 weiß man nur, dass
es größer ist als x2 = 4, dann kann
man den Mittelwert nicht angeben, aber für den
empirischen Median gilt  , gleichgültig
wie groß x3 ausfällt. Aus dieser
Beobachtung folgt, dass der empirische Median robust ist gegenüber Ausreißern. Dieser
Sachverhalt wird bei der Auswertung von Überlebenszeiten
noch eine Rolle spielen.
, gleichgültig
wie groß x3 ausfällt. Aus dieser
Beobachtung folgt, dass der empirische Median robust ist gegenüber Ausreißern. Dieser
Sachverhalt wird bei der Auswertung von Überlebenszeiten
noch eine Rolle spielen.
Man kann den empirischen Median auch
mit Hilfe der empirischen Verteilungsfunktion Fn
definieren.
Fn gibt
für jedes x auf der Zahlengeraden an, wie groß
der Anteil der Daten ist, die kleiner oder gleich x
sind. Für x(1), den kleinsten Wert,
gilt
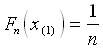 ,
,
- aber nur falls alle Daten voneinander
verschieden sind - für x(n),
den größten Wert, gilt
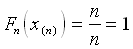 .
.
Damit ist der empirische Median 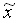 der kleinste Wert, für den gilt
der kleinste Wert, für den gilt
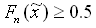 .
.
Entsprechend definiert man mithilfe der
empirischen Verteilungsfunktion als weitere Lagemaße die
sogenannten empirischen Quantile xp (0<p<1)
: xp ist der
kleinste Wert, für den gilt: Fn(xp)
>= p. Insbesondere werden x0.25
und x0.75 betrachtet. x0.25
heißt 1. Quartil, x0.75 3. Quartil. In
dieser Terminologie ist der empirische Median das 2.
Quartil
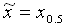
In Analogie zur Berechnung des Medians werden die Quartile oft folgendermaßen berechnet.
Die gesamte Rangliste wird in zwei Hälften geteilt.
Das erste Quartil
ist der Wert "in der Mitte" der ersten Hälfte der Rangliste, d.
h. die Hälfte der halbierten Meßreihe sind kleiner bzw. größer als das erste Quartil. Analog wird das 3. Quartil berechnet.
Das oben beim Median erwähnte Verfahren bei geraden Anzahlen den Mittelwert der Rangwerte (n/2) und (n/2 +1) zu verwenden, wird oft auch bei der Quartilsberechnung benutzt.
Streuungsmaße sind Maßzahlen für die Abweichung der Meßwerte vom Durchschnittswert. Die bekanntesten Streuungsmaße sind
die empirische Varianz s2
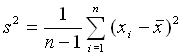
und die empirische Standardabweichung
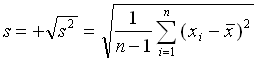
Wegen des Quadrierens lässt sich die
empirische Varianz als Zahlwert anschaulich kaum
interpretierten, während sich die empirische
Standardabweichung grob als mittlere Abweichung der Daten
von ihrem Mittelwert deuten lässt.
Als weitere Streuungsmaße betrachtet
man die empirische Spannweite R (engl.: range):
R = xmax-xmin
= x(n)-x(1)
und den empirischen Interquartilsabstand
q = x0.75-x0.25
.
Die empirische Spannweite ist offenbar
extrem ausreißerempfindlich, der empirische
Interquartilabstand ist ein stabileres Streuungsmaß.
Mit dem Adjektiv "empirisch"
bei den Maßzahlen, soll betont werden, dass sich diese
Maßzahlen tatsächlich aus der Stichprobe berechnen
lassen. Später sollen sie den analogen Maßzahlen der
Grundgesamtheit gegenübergestellt werden, die sich
zumeist nicht berechnen lassen. Vielmehr werden die
empirischen Maßzahlen der Stichprobe als Schätzwerte
für die theoretischen Maßzahlen der Grundgesamtheit
dienen. Wenn aus dem Zusammenhang ersichtlich ist, ob die
Grundgesamtheit oder die Stichprobe gemeint ist, soll in
Zukunft das Adjektiv empirisch entfallen.
Beispiel 2.4
In Tabelle 2.5 finden Sie für 16
weibliche Patienten einer Klinischen Studie die Angaben
zur Körpergröße in cm. Die Daten liegen in Form einer
Rangliste vor, d. h. sie sind bereits aufsteigend
sortiert.
Tabelle
2.5: Körpergröße von 16 Patienten
Aus den Werten der Tabelle 2.5 erhält man die folgende graphische Darstellung der empirischen Verteilungsfunktion.
Abbildung 2.6: Empirische Verteilungsfunktion für das Merkmal Größe

Applet - Explorative Datenanalyse -- Datensatz "AML" - Verteilungsfunktion "Größe"
Aus den Werten der Tabelle 2.5 erhält man die folgenden Lagemaße und Streungsmaße.
Lagemaße
empirisches Minimum xmin
= 155
empirisches 0.25-Quantil (1. Quartil) x0.25
= 159
alternativ 0.5*(x(4) + x(5)) =160.5
empirischer Median (2. Quartil)  165
165
alternativ x0.5 =165
empirisches 0.75-Quantil (3. Quartil) x0.75
= 167
alternativ 0.5*(x(12) + x(13)) =168.5
empirisches Maximum xmax = 176
Mittelwert 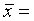 165.1875
165.1875
Streuungsmaße
empirische Spannweite (Range) R = xmax-xmin
= 21
empirischer Interquartilsabstand q = x0.75-x0.25
= 8
empirische Varianz 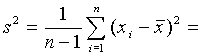 36.0292
36.0292
empirische Standardabweichung 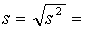 6.0024
6.0024
Javascript - Statistische Maßzahlen
Applet - Explorative Datenanalyse -- Datensatz "AML" - Basisstatistik "Größe" 
2.5 Boxplot
Der Boxplot ist eine graphische Darstellung, mit der man
sich einen guten Überblick über die Verteilung der
Daten einer Stichprobe verschaffen kann.
In einem Koordinatensystem, an dessen
y-Achse eine Skala für das betrachtete Merkmal
abgetragen ist, wird der Interquartilsabstand q
als Kasten (engl.: box) eingezeichnet. Vom oberen Ende
des Kastens wird eine Strecke bis zum maximalen Wert
gezeichnet, die aber nicht länger als das 1.5-fache des
Interquartilsabstandes gezogen wird. Falls es Werte gibt,
die mehr als 1.5x q vom oberen Ende entfernt sind, so
werden diese einzeln als Punkte eingetragen.
Entsprechend verfährt man am unteren
Ende des Kastens mit dem minimalen Wert. Zusätzlich wird die Position des
empirischen Medians und manchmal auch die des
Mittelwertes markiert. In dieser Definition umfasst der
Kasten gerade die mittleren 50 % der Daten. Es gibt auch
andere Varianten des Boxplots. Wenn man statistische
Software benutzt, muss man prüfen, ob diese oder eine
andere Definition benutzt wird.
Die Darstellung als Boxplot ist sehr
nützlich, insbesondere dann, wenn man Untergruppen der
Stichprobe vergleichen will.
Beispiel 2.5
Tabelle 2.6 enthält die statistischen Angaben
für alle 140 Patienten (59 männliche, 81 weibliche) einer Studie.
Tabelle
2.6: Basisstatistik: Körpergröße
| Größe |
Geschlecht
|
| |
Männlich
|
Weiblich
|
| N |
57
|
76
|
| fehlend |
2
|
5
|
| xmin |
160.00
|
148.00
|
| x0.25 |
171.00
|
160.00
|
|
176.00
|
165.00
|
| x0.75 |
180.00
|
170.00
|
| xmax |
190.00
|
180.00
|
|
176.12
|
164.87
|
| empirische Spannweite R |
30.00
|
32.00
|
| empirischer Interquartilsabstand
q |
9.00
|
10.00
|
| s2 |
49.72
|
44.76
|
| empirische Standardabweichung
s |
7.05
|
6.69
|
Aus den Angaben in
Tabelle 2.6 erhält man in Abbildung 2.7 einen nach Geschlecht
getrennten Boxplot für die Körpergröße. Hierbei wird die Lage des arithmetischen Mittels durch einen roten Punkt dargestellt.
Abb 2.7: Boxplot für das Merkmal Körpergröße
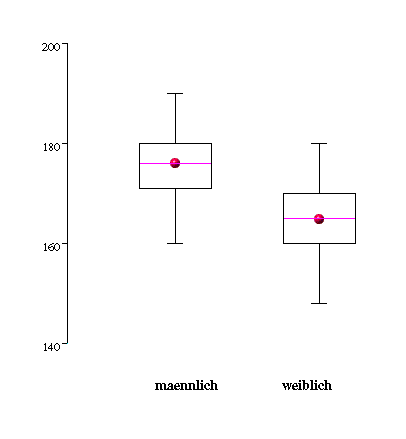
Applet - Explorative Datenanalyse -- Datensatz "AML" - Boxplot "Größe" mit Split "Geschlecht" 
Applet - Dot Plot, Diamond Plot, Box Plot
Die Quantile werden in der Medizin
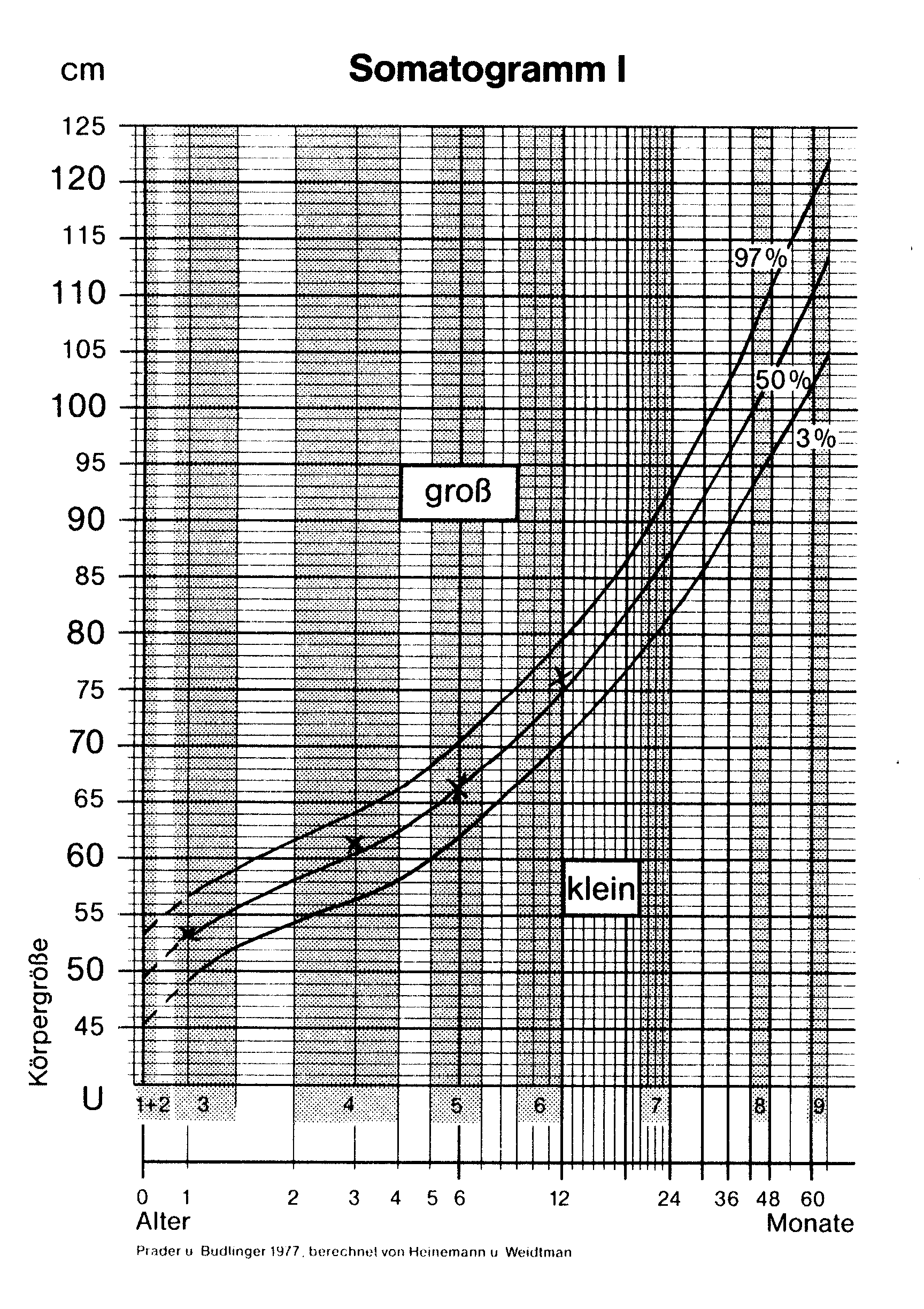
häufig angewandt z.B. zur Festlegung von Normbereichen. Abbildung 2.8 zeigt ein Diagramm, in das
bei den Säuglingsvorsorgeuntersuchungen die
Körpergröße in Abhängigkeit vom Alter eingetragen
wird. Dargestellt sind das 0.03-Quantil, der Median und das 0.97-Quantil der Körpergröße in Abhängigkeit vom Alter des Kindes. Im Bereich zwischen den Quantilen befinden sich etwa 94% der Grundgesamtheit. Kinder, deren Körpergröße dauerhaft nicht in diesen Bereich fällt, gelten als auffällig groß bzw. auffällig klein. Bei ihnen wird untersucht, ob eine Entwicklungsstörung vorliegt.
Abbildung
2.8: Somatogramm
2.6 Häufigkeitsmaße in der Epidemiologie
In diesem Abschnitt werden die wichtigsten epidemiologischen Maßzahlen definiert.
Die Neuerkrankungsrate oder Inzidenz einer bestimmten Krankheit
ist der Anteil der Personen einer definierten Population, die in einem
bestimmten Zeitraum (ZR) an dieser Krankheit neu erkranken:
Inzidenz = (Anzahl der neu Erkrankten im ZR)/(Anzahl der Personen der Population im ZR)
Die Prävalenz einer bestimmten Krankheit ist der Anteil der Personen
einer definierten Population, die zu einem bestimmten Zeitpunkt (ZP)
erkrankt sind:
Prävalenz = (Anzahl der Erkrankten zum ZP)/(Anzahl der Personen der Population zum ZP)
Die Todesrate oder Mortalität ist der Anteil der Personen einer definierten Population, die in einem bestimmten Zeitraum (meist 1 Jahr) sterben:
Mortalität = (Anzahl der Gestorbenen im ZR)/(Anzahl der Personen der Population im ZR)
Angaben über die Mortalität können auch auf eine bestimmte Krankheit bezogen sein:
Mortalität =(Anzahl der infolge der Krankheit Gestorbenen im ZR)/(Anzahl der Personen der Population im ZR)
Die Letalität ist der Anteil der an einer bestimmten Krankheit in
einem bestimmten Zeitraum (meist 1 Jahr) Gestorbenen, bezogen auf
die Gesamtanzahl der an der betrachteten Krankheit Erkrankten einer
definierten Population:
Letalität = (Anzahl der an der Krankheit Gestorbenen im ZR)/(Anzahl der Erkrankten im ZR)
Die Letalität wird nur für akute Erkrankungen betrachtet, bei denen
man davon ausgeht, dass die Erkrankung und deren Ausgang in der
Regel in den gleichen Zeitraum fallen.
Alle Maßzahlen sind relative Häufigkeiten und beziehen sich auf eine
definierte Grundgesamtheit(Population) und einen definierten Zeitraum. Inwieweit die jeweils berechnete Maßzahl sinnvoll interpretiert
werden kann, muss im Einzelfall geprüft werden:
- Die Inzidenz hat wenig Aussagekraft bei Erkrankungen, an denen
eine Person während des betrachteten Zeitraums mehrfach erkranken kann.
- Die Angabe der Letalität hat nur bei akuten Erkrankungen einen
Sinn.
- Die Angabe der "Anzahl der Personen der Population im ZR" bedarf im konkreten Fall der genauen Erläuterung.
Beispiel 2.6
In den entsprechenden Veröffentlichungen des Statistischen Bundesamts, der Statistischen Landesämter sowie in den
Schriftenreihen der zuständigen Ministerien und Krebsregister findet man z. B. folgende Angaben:
o In der Bundesrepublik kommen pro Jahr 40 Herzinfarkte auf je
10 000 Einwohner (Inzidenz).
o In der Bundesrepublik gibt es 350-000 Epileptiker, d. h. etwa 50
auf je 10 000 Einwohner (Prävalenz).
o In der Bundesrepublik gab es 1990 71 300 Todesfälle durch Herzinfarkt. Bei ca. 80 Millionen Einwohnern ergibt sich daraus eine Mortalität von ca. 0.09 % (71 300/80 000 000).
o Die Letalität der akuten lymphatischen Leukämie bei Kindern ist
von 100% im Jahre 1970 auf 30% im Jahre 1990 zurückgegangen.
Applet-Graphische Darstellung von qualitativen Merkmalen
Applet-Explorative Datenanalyse
Histogramm-Applet
Javascript - Statistische Maßzahlen
Applet - Dot Plot, Diamond Plot, Box Plot
Applet - Histogramm und Normalverteilungsplot
MC-Fragen zu Kapitel 2 
Übungen zu Kapitel 2 
Musterlösung zu den Übungen 
Ein Kapitel weiter 
Ein Kapitel zurück 
Zurück zum Inhaltsverzeichnis 